







In 2022, Meta’s Infrastructure teams were struggling to provide state-of-the-art AI hardware to our product groups in industry-leading time. Furthermore, some of our recent deliveries had also fallen short of expectations.
We had one more chance to deliver.
This post delves into some important changes we put in place to completely turn these challenges around, as well as how these changes have evolved over the subsequent two and a half years.
First, a little background: New product introduction (NPI)
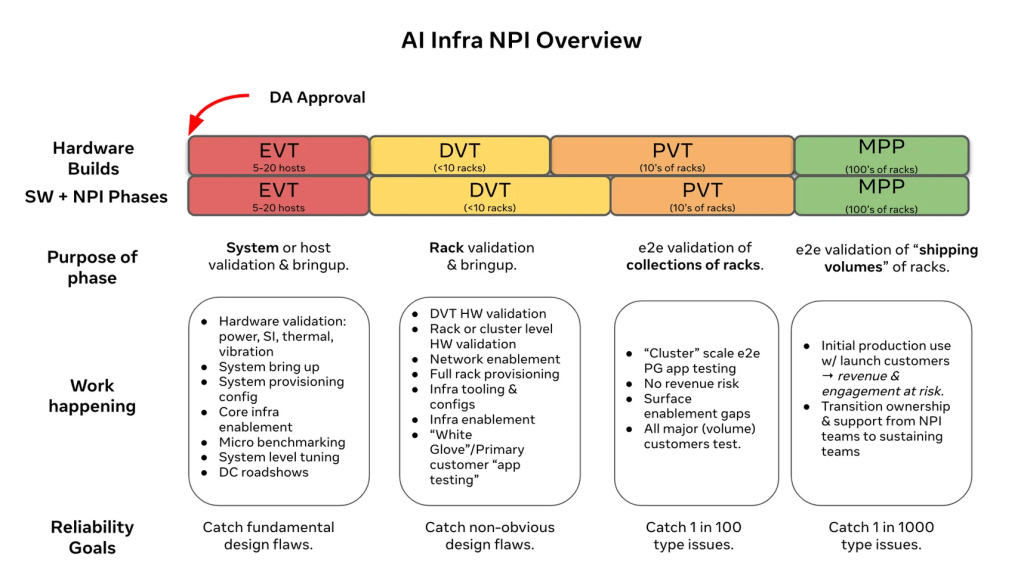
For those who aren’t immersed in the hardware industry, there’s a bit of technical jargon that is worth understanding before we begin our story. Hardware is developed by following a process called New Product Introduction or “NPI.” The exact process varies by company, but at Meta we manage our hardware life cycle with seven major phases:
- Concept
- Hack
- PoR/Design
- Engineering Validation & Test (EVT)
- Design Validation & Test (DVT)
- Production Validation & Test (PVT)
- Mass Production (MP)
The NPI is everything before MP. Figure 1 below summarizes the process.

In short, this process exists to help guide a hardware platform from initial design to its introduction into our production data centers, where it then serves our production workloads. It is a mature process that’s been in place for more than a decade, and it’s used to bring to production virtually every SKU we have in production today at Meta.
Ok, back to our original programming …
Prologue
To understand our prior missteps and the lessons we have learned since, let’s briefly review Meta’s historical hardware strategy and the motivation behind it, as well as the AI hardware landscape of the 2010s.
Pioneers versus Pragmatists
Historically, Meta has employed a “fast-following” hardware-deployment strategy, whereby we observe industry hardware and software trends and then quickly move to adopt the solutions that have proven themselves and become dominant. This avoids resource intensive product design mistakes at the expense of a longer time-to-production (TTP). Important to this approach are rapid product-development cycles, to ensure the TTP gap isn’t excessively long, and a software stack that was largely agnostic to the underlying compute or storage hardware.
This approach served us well for over a decade as we grew from a modest startup to the tech giant we are today. This strategy saw the successful introduction of a variety of compute and storage platforms used to power our web and mobile applications, the majority of which were open sourced via the Open Compute Project (OCP):

That is, until the AI revolution began to gather steam around 2019.
To GPU or not to GPU, that is the question
Today we take it for granted that GPUs are an important piece of hyperscale infrastructure, but in the early to mid 2010s, it was anything but clear this was the right approach. Back then, one of the major industry debates was whether CPUs or GPUs should be used to power machine learning, with strong opinions on both sides. CPUs offered tried-and-true programming paradigms, well-understood hardware platforms, and existing large-scale deployments; in contrast, GPUs offered massive increases in computational power but were resource intensive, had very different programming paradigms, and few engineers had the necessary GPU programming expertise.
By 2019, it was becoming clear that GPUs with dedicated high-speed back ends were the right approach, and Meta embarked on a journey to rapidly introduce these systems in our data centers. The initial introductory steps included:
- Experimentation
- We deployed “pods” of GPUs—100s of V100 GPUs connected by RoCE for an experimentation partnership between our product groups and infrastructure teams. The purpose was to evaluate the potential benefit to Meta’s Deep Learning Recommendation Model (DLRM) workloads.
- This experimentation required more than major infrastructural changes, but our training paradigms themselves needed to change to take advantage of the GPUs and this network topology. As such, we shifted from asynchronous to synchronous training.
- The experiments were immediately successful, and we pivoted in a major way. This required some innovation.
- Innovation
- With the value proposition clear, we evolved our Zion platform to be Meta’s first RoCE-supported training SKU, ZionEX. In Figure 3 below, note the eight RDMA NICs to facilitate our back-end fabric attached to our accelerators.
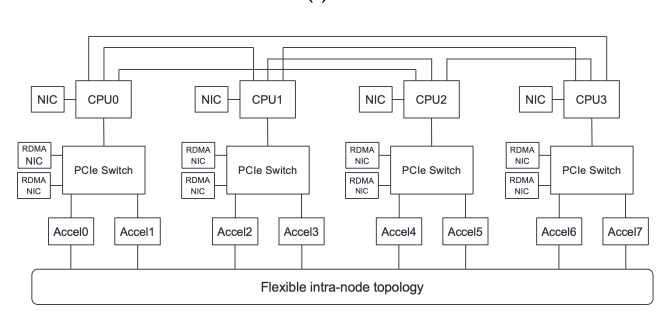
We also designed and deployed one of the world’s largest RoCE “back-end” networks to facilitate larger workload scale and more flexible job scheduling. Taking queues from our past infrastructure experience, we wanted to present a simple scheduling solution to our production groups that allows flexible job placement and efficient “bin packing” of our training jobs.
Of course, this hardware does not function in isolation. As depicted in Figure 4 below, to feed this amount of training infrastructure, we required a substantial amount of storage and supporting-service infrastructure (e.g., data ingestion and core infrastructure support).
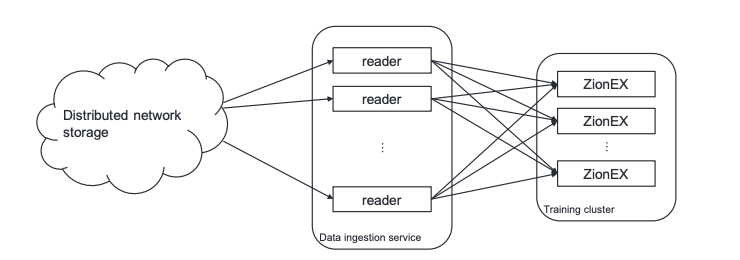
Within two years, training at Meta was very different for many of our major workloads. We had substantially more performance, thanks for new training solutions, a state-of-the-art network, and a horde of GPUs.
But then some cracks emerged.
Check your priors
Fast forward to 2021: Our AI infrastructure was starting to look very different, and we were scaling fast.
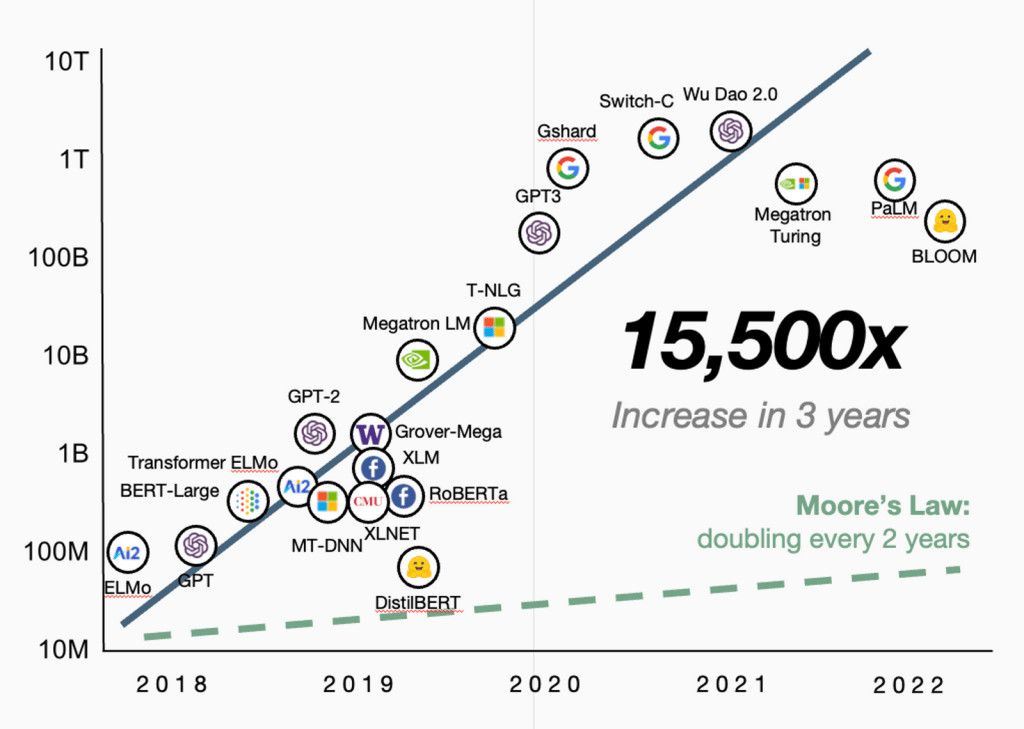
Remember that fast-following strategy that worked well for us for more than a decade? Well, the AI revolution was progressing at a breathtaking speed, and so was the hardware that powered it: New GPUs were being released every six to 12 months, with each generation considerably more powerful than the previous one. As far as AI hardware was concerned, Moore’s law was alive and well. Soon, two important assumptions we had held were broken.
The first: Hardware would evolve at a slow enough rate that fast following would keep us sufficiently close in efficiency and performance to our industry peers. But GPUs, memory, networking, and overall system design were evolving very quickly, with significantly different generations of hardware being released every nine to 12 months.
The second: Our software stack would be more or less agnostic to the compute hardware. While true for mature caching, storage, or data analytics infrastructure, nothing could have been further from the truth for AI. Bleeding-edge models like LLMs were tuned like Formula 1 cars to squeeze every ounce of performance out of their hardware, with results speaking for themselves.
These two factors combined, 12 months of TTP lag is like a lifetime. You’re essentially out of the AI race before you even make it out of the starting gate.
Further hampering matters, we were in the middle of a pandemic. This materially impacted our ability to source materials (both in the quantities needed and by necessary deadlines), didn’t allow engineers to meet face to face to discuss complex ideas, prevented visits to important hardware vendors, and ultimately required us to make major and sometimes high-risk decisions to bring sufficient capacity up. It was in this environment that we had to develop what were the most complex hardware platforms we had ever built and brought to production.
The result of all this? ZionEx racks went into production some 20 months after A100 was generally available (GA)—way behind our industry peers.* To say our ML researchers and engineers were upset is a bit of an understatement. Nobody likes reading papers or using products built on hardware you can’t get your hands on for another year.
Even worse, there were end-to-end (E2E) reliability issues. Training jobs frequently failed, stalled, or ran inconsistently, failures were difficult to diagnose, and training-framework support was patchy, leaving users with few tools to figure out how to rescue their training jobs.
Internally, this caused a lot of tension between our various product and infrastructure organizations. Escalations were common. Meta’s ability to even deploy reliable hardware in a timely manner (as we had done for nearly the entire decade before) was called into question. This was a huge wake-up call for our infrastructure orgs.
*It’s important to note that we were still “fast followers” and made a variety of important pivots along the way. Still, the frustration was real.
One last chance…or else.
It was against this backdrop that our H100-based Grand Teton platform began its NPI. We initiated this program with an explicit mission of delivering the platform in market-leading time to production (i.e., TTP, the time between the supplier GA date and our internal GA equivalent), and with exceptional production level, reliability, training-framework support, and tooling.
There was a sense that if we couldn’t get this delivered—and fully functional—at an industry-leading TTP, this might be the last AI hardware platform we would build. For a company like ours, where products are paramount, our hardware efforts are ultimately in service of those products—not the other way around.
To give ourselves the best chance of success, we did what we think most engineers might do: We studied our predecessors to see what we could learn, compared what had been done with our own experiences in NPIs (storage and compute), and documented best practices. This included poring over the various artifacts from prior AI NPIs, including all of the many internal documents and Development Approval/EVT/DVT/PVT exit decks that we could get our hands on.
In this way, we discovered a major disconnect in “production readiness.” If you were a hardware engineer, it might be perfectly reasonable to define this as having validated functionality, performance, and reliability as well as having reliable boot capabilities, functional drivers, an OS, and the necessary libraries required to support end customers. If you were in our Core Systems teams, you might add to that list: functional debug, device health tooling, and repair automation work. But if you were an Ads ML engineer, you would define it to include enablement of infra services such as our scheduler, our ingestion services, our training frameworks such as Pyper, MVIA, and APS…and, of course, that your workloads have the E2E performance and important, expected reliability.
These are all perfectly reasonable definitions of “in production.”
However, let’s consider the ZionEX example again: Having solid, validated hardware that we can manufacture and land at scale was not sufficient to provide value to our product groups. It was not until we had sufficient hardware with installed networking, storage, and data-ingestion services running, and had created our own onsite integration of an entire E2E training system, that we were able to give PGs a fighting chance of using ZionEX. This was the case especially because, as mentioned above, our training ecosystem is massive and it all has to work seamlessly for our product groups to take full advantage.
This was just one example; we had others where this divergent definition of “in production” caused major tensions.
In all cases, we landed hardware that was not able to serve our business.
Lessons Learned
Our study of and reflections on our 2019-2021 experiences highlighted four clear lessons:
Lesson 1: NPIs are not just about the hardware
Product (Product Group) enablement is paramount
For our Grand Teton NPI, we turned this everything on its head. In the aftermath of the iOS14 privacy update, our product groups needed a state-of-the-art GPU (the H100) in an industry-leading time for them to be competitive. And not just have it physically in our data centers: The entire HW/SW stack needed to work. Thus, our NPI objective had to be:
How quickly can we get our top-five product groups to run production workloads and meet their production-performance and reliability expectations?
This required us to be exceptionally clear on what “in production” meant—making clear it went beyond hardware, tooling, and fleet management. To this end, we broke down the NPI into roughly six axes (sometimes three to six, depending on the scope of the program), each having their own definition of “in production” guiding what would be overall NPI exit criteria. Each axis needed to achieve its NPI goals for the overall platform to be “in production.” The axes are listed in Figure 6 below:

Note that all the definitions mentioned earlier are now included here, including our product group/workload readiness criteria.
These axes are also useful because we can treat progress in each of them independently. A tangible example is how our board/server tape-outs now can be readily decoupled from unrelated deliverables and we can more cleanly prioritize work and identify critical paths.
This means that not only do we deliver more scope, but we do so faster.
With this updated definition, we were guaranteed to fulfill our commitment to our product groups. We would even have them “sign off” before we officially handed the platform over. Thus, they needed time within the NPI to validate our work.
This brings us to the next lesson learned.
Lesson 2: Keep PVT “clean.” Even sacrosanct.
Another takeaway from examining the prior AI NPIs was how much enablement and hardware-management tooling work was bleeding into our PVT process. This was a slippery slope, as this final NPI phase can and did become overloaded. Furthermore, while we were running representative benchmarks and workloads, these jobs were typically not actually run by engineers from the PGs who were the customers of the hardware. They were often run on “bare metal systems” and sometimes used different training frameworks. To be sure, all of this work was valuable and necessary, but it was happening too late in the NPI, and so E2E readiness had continued to shift right.
Over the years, it became clear we had drifted from the original intent of this phase, which was to hand over hardware to application owners or PGs for full E2E testing of their software stacks. This is something that we’d long done on our general compute and storage NPIs of old. PVT had lost its meaning and purpose—production validation and test—in our AI NPIs
Fixing this was two-fold.
Product groups get a “veto”
First, given the frustration of our product groups—our end customers—we needed to give them a seat at the table during PVT and DVT exit, and make it clear that they had the power—even the duty—to block exits if they believed the hardware and software stack were not ready for production. On the flip side, with this power came the responsibility to dedicate significant bandwidth to the NPI process to ensure their requirements were being captured during DA approval, review benchmarking data, ensure right workloads were being tested in DVT, and do hands-on evaluation of the E2E HW/SW stack during the PVT.
It’s worth stressing this last part again: By left-shifting performance validation and E2E enablement work heavily, you get the signal when you need it—before you tape-out your PVT hardware. It does little good to find out you’ve got a serious hardware issue during PVT or pilot, when your mitigation options are very limited, instead of making the appropriate hardware design change (e.g., adding retimers); you might be left with taking a performance hit that reduces the value of the platform.
And yes, substantial hardware testing is still done to build confidence in tape-out signals, but we’ve found that workloads augment this coverage well and can find real edges in hardware and/or firmware well. Now, we are discovering these well before we are in production, meaning fixes will land when we need them.
Got to hold the bar
The second piece to this puzzle was less about process and more about people. We needed a strong core of engineers, EMs, and TPMs who trusted each other, were trusted by their respective teams/orgs, and would be willing to hold a high bar on DVT and PVT exit criteria. We can’t stress the trust piece enough here, as at times part of everyone’s job during the NPI means having to deliver bad news to leadership that they might not wish to hear, field difficult questions at reviews, or push teams to make compromises or take risks with which they might not be comfortable.
Lesson 3: The importance of left-shifting enablement and performance validation into DVT
Now, you might be wondering, while this all sounds good in principle, if the work that was leaking into PVT can’t happen then, when will it get done? How will it get done? Why was it leaking into PVT in the first place?
Good questions, and ones the team asked as it created an aggressive NPI schedule, where as much work was “left-shifted” (see Figure 7, below) into DVT as possible.

To accomplish this, we did four things:
- required unbuffered/unpadded time estimates
- critical path identification & management
- decoupled hardware tape-outs* from phase exits
- deployed “skunkwork” methodologies
*Tape-out is blessing the next PCB/server revision designs and builds
Requiring unpadded time estimates
By default, most teams tend to add some amount of buffer to any time estimate they might give when participating in an XFN effort; after all, nobody wants to be the reason for the delay of a large effort. Given the large numbers of teams involved in NPIs, however, this resulted in a heavily bloated schedule and execution that were likely expanding to fill the originally planned timeline.
How did we know our schedules were bloated? Well, our peers were delivering the same training platforms into their production environments over a year before we were, and in one case, some 20 months earlier. In the winner-take-all, fast-paced AI race, this was inexcusable.
Instead, teams needed to deliver bufferless estimates, and any schedule buffer would be shared amongst the teams and managed by the TPM and TLs of the NPI program.
Critical path identification and management
Furthermore, for large efforts such as an NPI, there are thousands (or tens of thousands) of individual work items, with many interdependencies. Identifying the critical path can be difficult but also powerful if time is taken to do it.
Given the stakes of the Grand Teton project, we entered every single work item—complete with dependencies—into a project-management tool and identified our critical path. This allowed us to concretely identify our “long poles” and dramatically reduce them (by advocating for resources, figuring out ways to decouple work streams, and scrutinizing time estimates). This was recursive. In fact, we repeated this process multiple times until we reached a point of diminishing returns.
A secondary benefit to knowing our critical path resulted from assessing delays or unexpected problems in the execution of work items. We could quickly determine whether they were immaterial or something we needed to worry about.
Decoupling hardware tape-outs from other NPI phases
This was one of the bigger changes we put in place. As mentioned in Lesson 1, at some point NPIs became overly focused on hardware, and what flowed from this were NPI phases that themselves became synonymous with hardware quality, thus elongating each phase substantially (despite the slips mentioned above).
With the NPI phase axes (shown in Figure 6 above), we were able to create parallel workstreams within the NPI that had minimal interdependencies (though zero would be impossible). Each had their own deliverables and “exit criteria” allowing us to independently assess hardware quality, address hardware issues, and rapidly iterate on the hardware build quality.
Decoupling was important. Hardware has (at least relatively speaking) long validation and build timelines, so we can focus intensely on validation with initial builds, identify issues/bugs and their fixes, and iterate. The rest of the work items can operate in parallel, subsequent to the validation sprints. (Note: Validation of course continued contiguously throughout, but there was an intense focus on it initially).
As a consequence, teams no longer had to wait until PVT-quality hardware landed to commence work that needed it, because hardware builds were now moving faster than they were (depicted in Figure 8, below).

The value of skunkworks
Given the recent history described above, and that Meta had become a fairly large company, we still had some lost trust and risk aversion between orgs. We realized we needed to get a core group of engineering leads together who were comfortable throwing away existing paradigms and didn’t mind breaking eggs as they were making this new “omelette,” as the saying goes.
As such, we had a skunkworks project that quietly operated to enable our production workloads in “lightspeed”—literally as fast as we possibly could. We’d receive an engineer sample or engineering FW release and have it installed and tested with real workloads within hours.
Consequently, we had major wins very early in our NPIs, which helped lift the morale of the entire team, build trust, and both support and strengthen our focus on the next, bigger milestone.
Promising initial results
Through all of this, we were likely one of the first companies that got E2E workloads running on an H100 system (it would have been practically impossible to do so much sooner). This early enablement gave us way more server hours of job run time within the NPI and thus to tune performance and debug/fix issues across the entire stack.
Our 20 month time-to-production on ZionEX had been reduced to four months for Grand Teton.
Ultimately, this meant we could ramp up our Grand Teton fleet aggressively, since we knew we could utilize the racks after PVT exit, as shown in Figure 9 below:

The results compounded
As Grand Teton was coming to a close, Meta began our MTIA Artemis program. For various reasons, this was important for us to deploy with similar quality as—but even faster speed than—Grand Teton.
We embarked on this NPI with an even more audacious goal: a one-month time to production—which we achieved! What made this project especially challenging was extra NPI “axes” associated with Silicon (pre-/post-Silicon work) and firmware development that we brought in from outside Meta.
These extra NPI axes effectively increased the total number of server hours that we require to fully release a new platform to production. Which brings us to the next lesson…
Lesson 4: Parallelize the world
NPI’s are a complex undertaking, with tens of teams and hundreds of individual work items. Just how complex are they? Well, the (collapsed) high-level Gantt chart of the Grand Teton program in Figure 10 below offers a sense of the complexity.

In this sort of effort, high parallelism is absolutely important, as well as ensuring you have the necessary resources to maximize.
A crude resource model of the NPI is the sum total of individual tasks multiplied by the number of servers and time required to complete that task. There are of course dependency concerns, but the idea here is we don’t want dependencies to exist due to hardware shortages.
As several of our recent NPIs have been driven by a need for delivering a platform into production at a certain time, the time aspect of this metric is fixed. Our ability to do work is therefore determined by the number of servers we have in the NPI.
Especially for short time-to-production platforms, we have to develop on more servers. This enables the NPI teams to further parallelize work. The counter point is perhaps more valuable: Without sufficient hardware, there is an explicit tradeoff that must be done on work items. Without a time demand, the time duration of an NPI will be longer (which may be perfectly acceptable on many platforms). With a time demand, the above NPI axes will vie for priority access to a limited number of machines. The program TLs and EMs will have to prioritize what’s most important, and some things will be dropped.

Lessons 2 and 3 discussed the value of early workload enablement, the value of which is delivered only if we have an ample supply of hardware to run it on. We need to plan deliberately for an NPI capacity that will support our workloads.
Closing thoughts
Our overall NPI process now looks something like Figure 12 below (concept and hack phases excluded for brevity):
To be sure, our AI NPI teams are by no means perfect on our NPIs, exceptions happen from time to time, and it’s simply not possible to catch some spurious 1-in-1000-type HW bugs during PVT (enter MP Pilot, aka MPP). Additionally, adoption of these methodologies is resource intensive in terms of engineering hours and challenging due to the sheer number of NPIs in flight.
And finally, it’s noteworthy, even ironic, that nothing we’ve discussed here is actually that new to Meta. Indeed, you can find the NPI style we are advocating described in detail in a circa 2018 NPI/HW Life Cycle PowerPoint deck. So, if we did anything in AI Infra, we rediscovered Facebook’s old NPI playbook, dusted it off, and followed it as closely as we possibly could.
This journey is only 1% finished
In the future, the challenges of deploying AI hardware infrastructure will continue to grow. We will see significantly more complete architectures, from Silicon to “scale-up” domains trying to provide major performance benefits. Workloads are continuing to increase in scale. And companies are offering novel architectures that are worth exploring.
Meta has a saying that the journey is only 1% finished. Even when things feel “steady state,” we expect radical change.
And we do.